Differenza tra stack e coda

Contenuto
- Tabella di comparazione
- Definizione di Stack
- Esempio
- Definizione di coda
- Esempio
- Implementazione dello stack
- Implementazione della coda
- Operazioni in pila
- Operazioni su una coda
- Applicazioni di Stack
- Applicazioni di coda
- Conclusione

Stack e Queue sono entrambe le strutture di dati non primitive. Le principali differenze tra stack e coda sono che lo stack utilizza il metodo LIFO (last in first out) per accedere e aggiungere elementi di dati, mentre Queue utilizza il metodo FIFO (First in first out) per accedere e aggiungere elementi di dati.
Stack ha solo un'estremità aperta per spingere e far scoppiare gli elementi di dati dall'altra parte La coda ha entrambe le estremità aperte per accodare e dequefare gli elementi di dati.
Stack e coda sono le strutture di dati utilizzate per la memorizzazione di elementi di dati e in realtà si basano su alcuni equivalenti del mondo reale. Ad esempio, lo stack è uno stack di CD in cui è possibile estrarre e inserire il CD nella parte superiore dello stack di CD. Allo stesso modo, La coda è una coda per i biglietti del Teatro in cui la persona in piedi in primo luogo, cioè prima della coda verrà servita per prima e la nuova persona che arriva apparirà nella parte posteriore della coda (estremità posteriore della coda).
- Tabella di comparazione
- Definizione
- Differenze chiave
- Implementazione
- operazioni
- applicazioni
- Conclusione
Tabella di comparazione
| Base per il confronto | Pila | Coda |
|---|---|---|
| Principio di funzionamento | LIFO (Last in First out) | FIFO (First in First Out) |
| Struttura | La stessa estremità viene utilizzata per inserire ed eliminare elementi. | Un'estremità viene utilizzata per l'inserimento, ovvero l'estremità posteriore e un'altra estremità viene utilizzata per l'eliminazione di elementi, ovvero l'estremità anteriore. |
| Numero di puntatori utilizzati | Uno | Due (in una semplice coda) |
| Operazioni eseguite | Push and Pop | Enqueue e dequeue |
| Esame della condizione vuota | Top == -1 | Anteriore == -1 || Anteriore == Posteriore + 1 |
| Esame delle condizioni complete | Top == Max - 1 | Posteriore == Max - 1 |
| varianti | Non ha varianti. | Ha varianti come coda circolare, coda prioritaria, coda doppiamente chiusa. |
| Implementazione | Più semplice | Comparativamente complesso |
Definizione di Stack
Uno stack è una struttura di dati lineare non primitiva. È un elenco ordinato in cui viene aggiunto il nuovo elemento e l'elemento esistente viene eliminato da una sola estremità, chiamato come top of the stack (TOS). Poiché tutta la cancellazione e l'inserimento in una pila viene effettuata dalla cima della pila, l'ultimo elemento aggiunto sarà il primo ad essere rimosso dalla pila. Questo è il motivo per cui lo stack è chiamato tipo di elenco Last-in-First-out (LIFO).
Si noti che l'elemento a cui si accede spesso nello stack è l'elemento più in alto, mentre l'ultimo elemento disponibile si trova nella parte inferiore dello stack.
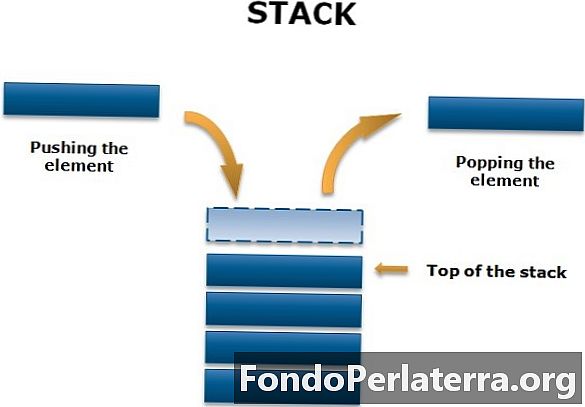
Esempio
Alcuni di voi possono mangiare biscotti (o Poppins). Se supponi, solo un lato della copertina viene strappato e i biscotti vengono rimossi uno per uno. Questo è ciò che si chiama scoppiare, e allo stesso modo, se vuoi conservare alcuni biscotti per un po 'di tempo dopo, li rimetterai nella confezione attraverso la stessa estremità strappata che si chiama push.
Definizione di coda
Una coda è una struttura di dati lineare che rientra nella categoria del tipo non primitivo. È una raccolta di tipi simili di elementi. L'aggiunta di nuovi elementi avviene a un'estremità chiamata posteriore. Allo stesso modo, la cancellazione degli elementi esistenti avviene all'altra estremità chiamata Front-end ed è logicamente un tipo di elenco First in first out (FIFO).
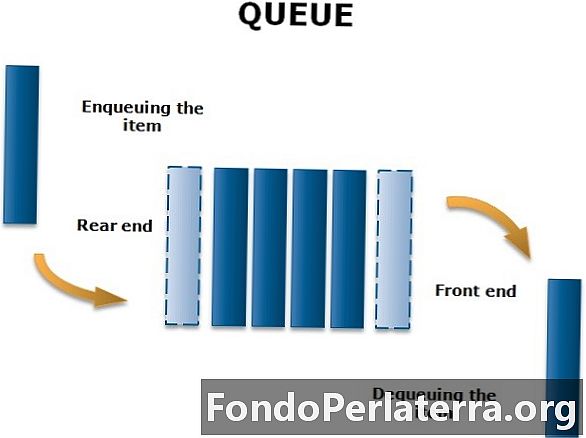
Esempio
Nella nostra vita di tutti i giorni ci imbattiamo in molte situazioni in cui aspettiamo il servizio desiderato, dove dobbiamo metterci in fila in attesa che il nostro turno venga assistito. Questa coda di attesa può essere pensata come una coda.
- Lo stack segue il meccanismo LIFO invece la coda segue il meccanismo FIFO per aggiungere e rimuovere elementi.
- In una pila, la stessa estremità viene utilizzata per inserire ed eliminare gli elementi. Al contrario, nella coda vengono utilizzate due estremità diverse per inserire ed eliminare gli elementi.
- Poiché lo Stack ha solo un'estremità aperta, questo è il motivo dell'uso di un solo puntatore per fare riferimento alla parte superiore dello stack. Ma la coda utilizza due puntatori per fare riferimento alla parte anteriore e posteriore della coda.
- Stack esegue due operazioni note come push e pop mentre in coda è noto come accodamento e dequeue.
- L'implementazione dello stack è più semplice mentre l'implementazione della coda è complicata.
- La coda ha varianti come coda circolare, coda prioritaria, coda doppiamente chiusa, ecc. Al contrario, lo stack non ha varianti.
Implementazione dello stack
Lo stack può essere applicato in due modi:
- Implementazione statica usa le matrici per creare una pila. L'implementazione statica è tuttavia una tecnica semplice ma non è un modo flessibile di creazione, poiché la dichiarazione delle dimensioni dello stack deve essere eseguita durante la progettazione del programma, dopo di che non è possibile variare le dimensioni. Inoltre, l'implementazione statica non è molto efficiente per quanto riguarda l'utilizzo della memoria. Poiché un array (per l'implementazione dello stack) viene dichiarato prima dell'inizio dell'operazione (in fase di progettazione del programma). Ora se il numero di elementi da ordinare è molto inferiore nello stack, la memoria allocata staticamente verrà sprecata. D'altra parte, se ci sono più numeri di elementi da archiviare nello stack, allora non possiamo essere in grado di cambiare le dimensioni dell'array per aumentarne la capacità, in modo che possa ospitare nuovi elementi.
- Implementazione dinamica è anche chiamato rappresentazione dell'elenco collegato e utilizza i puntatori per implementare il tipo di stack della struttura dei dati.
Implementazione della coda
La coda può essere implementata in due modi:
- Implementazione statica: Se una coda viene implementata utilizzando array, il numero esatto di elementi che vogliamo archiviare nella coda deve essere assicurato in precedenza, poiché la dimensione dell'array deve essere dichiarata in fase di progettazione o prima dell'inizio dell'elaborazione. In questo caso, l'inizio dell'array diventerà la parte anteriore della coda e l'ultima posizione dell'array fungerà da parte posteriore della coda. La seguente relazione fornisce tutti gli elementi esistenti nella coda quando implementati usando array:
anteriore - posteriore + 1
Se “rear <front” non ci saranno elementi nella coda o la coda sarà sempre vuota. - Implementazione dinamica: Implementando le code usando i puntatori, il principale svantaggio è che un nodo in una rappresentazione collegata consuma più spazio di memoria di un elemento corrispondente nella rappresentazione di matrice. Dal momento che ci sono almeno due campi in ciascun nodo uno per il campo dati e l'altro per memorizzare l'indirizzo del nodo successivo mentre nella rappresentazione collegata è presente solo il campo dati. Il merito dell'utilizzo della rappresentazione collegata diventa evidente quando è necessario inserire o eliminare un elemento nel mezzo di un gruppo di altri elementi.
Operazioni in pila
Le operazioni di base che possono essere gestite in pila sono le seguenti:
- SPINGERE: quando un nuovo elemento viene aggiunto all'inizio dello stack è noto come operazione PUSH. Spingendo un elemento nello stack si richiama l'aggiunta dell'elemento, poiché il nuovo elemento verrà inserito in alto. Dopo ogni operazione di spinta, la parte superiore viene aumentata di una. Se l'array è pieno e non è possibile aggiungere alcun nuovo elemento, viene chiamato condizione STACK-FULL o STACK OVERFLOW. FUNZIONAMENTO PUSH - funzione in C:
Considerando lo stack è dichiarato come
int stack, top = -1;
void push ()
{
int item;
if (inizio <4)
{
f ("Inserisci il numero");
scan ("% d", & item);
top = top + 1;
stack = item;
}
altro
{
f ("Lo stack è pieno");
}
} - POP: Quando un elemento viene eliminato dalla parte superiore dello stack, è noto come operazione POP. Lo stack viene ridotto di uno, dopo ogni operazione pop. Se sullo stack non è rimasto alcun elemento e viene eseguito il pop, ciò comporterà la condizione STACK UNDERFLOW, il che significa che lo stack è vuoto. POP OPERATION - funzioni in C:
Considerando lo stack è dichiarato come
int stack, top = -1;
void pop ()
{
int item;
if (top> = 4)
{
oggetto = pila;
top = top - 1;
f ("Il numero eliminato è =% d", elemento);
}
altro
{
f ("Lo stack è vuoto");
}
}
Operazioni su una coda
Le operazioni di base che possono essere eseguite in coda sono:
- Accodare: Per inserire un elemento in una coda. Funzione operazione di accodamento in C:
La coda è dichiarata come
coda int, anteriore = -1 e posteriore = -1;
void add ()
{
int item;
if (posteriore <4)
{
f ("Inserisci il numero");
scan ("% d", & item);
if (fronte == -1)
{
fronte = 0;
posteriore = 0;
}
altro
{
posteriore = posteriore + 1;
}
coda = articolo;
}
altro
{
f ("La coda è piena");
}
}
- dequeue: Per eliminare un elemento dalla coda. Funzione operazione di accodamento in C:
La coda è dichiarata come
coda int, anteriore = -1 e posteriore = -1;
void delete ()
{
int item;
if (fronte! = -1)
{
oggetto = coda;
if (anteriore == posteriore)
{
fronte = -1;
posteriore = -1;
}
altro
{
fronte = fronte + 1;
f ("Il numero eliminato è =% d", elemento);
}
}
altro
{
f ("La coda è vuota");
}
}
Applicazioni di Stack
- Analisi in un compilatore.
- Macchina virtuale Java.
- Annulla in un elaboratore di testi.
- Pulsante Indietro in un browser Web.
- Linguaggio PostScript per ers.
- Implementazione di chiamate di funzione in un compilatore.
Applicazioni di coda
- Buffer di dati
- Trasferimento dati asincrono (file IO, pipe, socket).
- Assegnazione di richieste su una risorsa condivisa (er, processore).
- Analisi del traffico.
- Determina il numero di cassieri da avere in un supermercato.
Conclusione
Stack e Queue sono strutture di dati lineari che differiscono in alcuni modi come meccanismo di funzionamento, struttura, implementazione, varianti, ma entrambe sono utilizzate per memorizzare gli elementi nell'elenco e per eseguire operazioni nell'elenco come aggiunta ed eliminazione degli elementi. Sebbene ci siano alcune limitazioni della coda semplice che viene ripristinata utilizzando altri tipi di coda.





